TAPESTRY: A Single Backbone for Video Generation and Robot Control
Jeremy A. Collins, Seungjae Lee, Rachanon Wachakorn, Krishnan Srinivasan, Animesh Garg,
Vitor Campagnolo Guizilini, Paarth Shah
In Submission
Paper |
Website
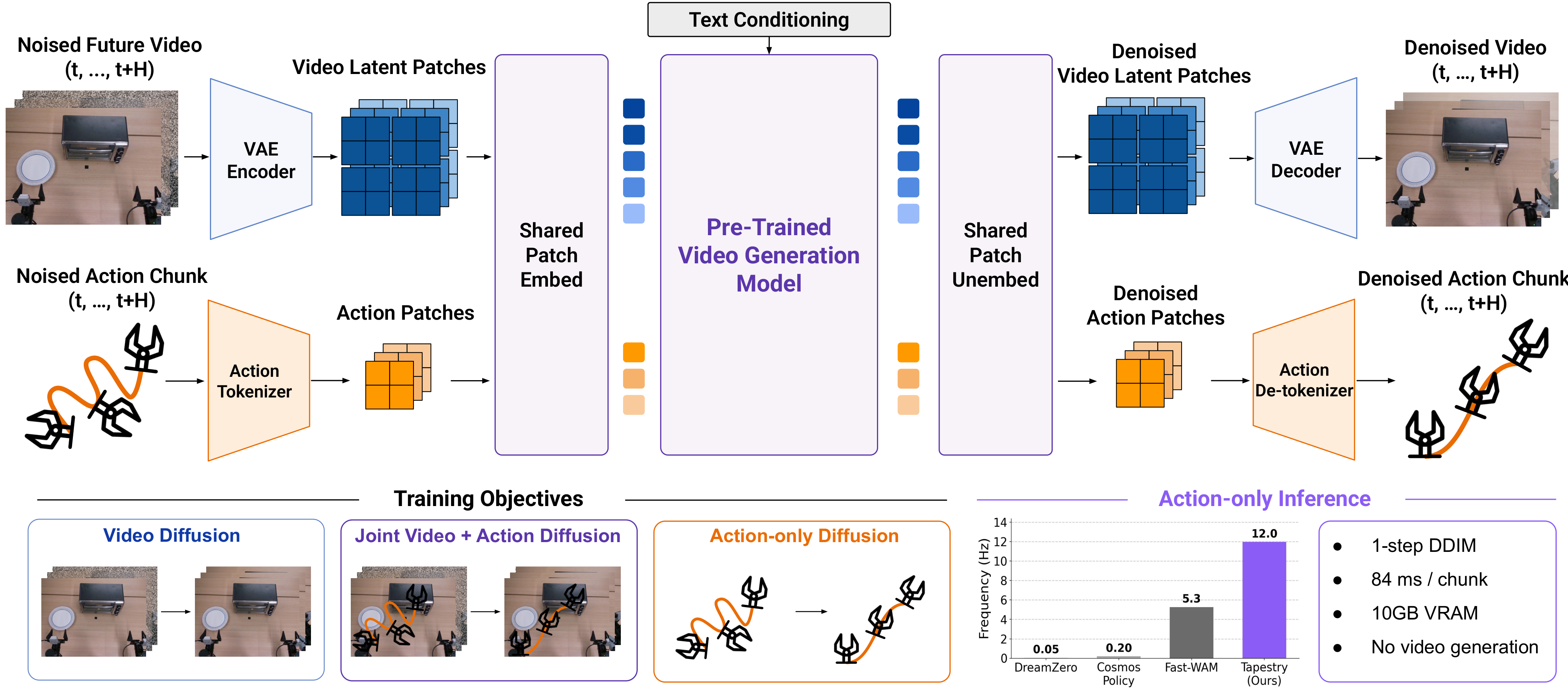
TAPESTRY treats robot actions as single patch tokens in the video model's latent space. Video latents and action patches share the same patch embedding layers and the same diffusion backbone. At test time, the model generates an action chunk in a single DDIM step from pure noise in 84ms on consumer hardware, no video generation required.